
Este es el primer artículo de programación que escribo en el blog, y tal y como transcurren las cosas imagino que le seguirán unos cuantos.
Tal y como indica el título tengo una serie de informes que quiero analizar, el problema es que la aplicación que los genera no funciona bien, se supone que genera un archivo .xls de excel pero tratas de abrirlo con excel te dice que no puede abrir archivos de ese tipo. Al abrirlo con un editor de textos se ve que en realidad son un archivo codificado en HTML. No se si es debido a un fallo de programación de la aplicación que lo genera, dudo que sepan lo que es la integración continua, o si esta hecho así a posta, aprovechando algún comportamiento extraño de versiones antiguas de excel. LibreOffice se lo traga y lo abre, pero elimina los espacios repetidos que para la integridad de la información que tiene el informe son importantes.
Al principio lo intenté con Python. Primero con HTMLParser, pero se comía los espacios con lo que estaba en las mismas. También trate de hacerlo con DOM y SAX pero no había manera por no estar el documento ‘bien formado’, además, al final se habrían comido los espacios igualmente y no me hubieran valido.
Al final me decidí a hacerlo desde cero, aprovechando un ejercicio de un examen de un curso de Java que estoy haciendo, donde había separar el texto de una cadena HTML según etiquetas.En el examen lo realicé todo en un mismo archivo con una simple máquina de estados, pero para resolver este problema decidí currármelo un poco más, separar el lexer del parser y crear una interfaz gráfica. El objetivo es aprender.
El lexer se basa en una máquina de estados que analiza un archivo de forma secuencial. Es una implementación muy básica, en el caso de las etiquetas HTML no analiza los atributos, el token resultante contiene todo lo que componga la etiqueta. Tampoco se tienen en cuenta los caracteres de escape salvo el que es el único que importa para los informes que tengo.
import java.io.IOException;
import java.io.Reader;
/**
* Analizador léxico que 'tokeniza' un informe en html compuesto por tablas -
* Solo 'escapa' el espacio &hbsp; - No analiza los atributos de las etiquetas
*
* @author Agustin Herranz
*/
public class Lexer {
/**
* Clase que guarda los 'tokens' analizados
*/
public class Token {
TokenType tipo;
String contenido;
public Token(TokenType tipo, String contenido) {
this.tipo = tipo;
this.contenido = contenido;
}
@Override
public String toString() {
String texto = String.format(" Tipo token: %s, contenido: \"%s\"%n"
, this.tipo.name(), this.contenido);
return texto;
}
}
/**
* tipos de tokens analizados
*/
public enum TokenType {
OPEN_TAG, CLOSE_TAG, CONTENT, ERROR
}
/*
* Estados posibles de la máquina de estados
*/
private enum Estado {
ETIQUETA, ETIQUETA_ABERTURA, ETIQUETA_CIERRE, CONTENIDO, ESCAPE
};
/*
* Variables de clase
*/
private Reader reader;
private String etiqueta;
private String contenido;
private String escape;
//modos de la maquina de estados
private Estado estado;
private Estado estadoAnterior;
/**
* Constructor, se le ha de pasar un Reader que apunte al fichero a
* analizar.
*
* @param text
*/
public Lexer(Reader text) {
this.reader = text;
this.etiqueta = "";
this.contenido = "";
this.escape = "";
//modos de la maquina de estados
this.estado = Estado.CONTENIDO;
this.estadoAnterior = Estado.CONTENIDO;
}
/**
* Ejecuta el analizador léxico
*
* @return un token válido o null
* @throws IOException
*/
public Token lex() throws IOException {
Token token = null;
//procesa el texto
int ch;
while (token == null && (ch = reader.read()) != -1) {
Character c = (Character) (char) ch;
switch (c) {
//carácteres ignorados
case '\t':
case '\r':
case '\n':
break;
//carácteres escape
case '&':
switch (estado) {
case ESCAPE:
token = new Token(TokenType.ERROR,
"Error, estado: " + estado.name());
break;
case ETIQUETA:
case ETIQUETA_ABERTURA:
case ETIQUETA_CIERRE:
case CONTENIDO:
estadoAnterior = estado;
estado = Estado.ESCAPE;
escape = "";
break;
default:
token = new Token(TokenType.ERROR,
"Error, estado: " + estado.name());
break;
}
break;
case ';':
switch (estado) {
case ESCAPE:
estado = estadoAnterior;
switch (escape) {
case "nbsp":
c = ' ';
break;
default:
//codigo de escape no soportado
token = new Token(TokenType.ERROR,
"Error. Codigo de escape no soportado:"
+ " &" + escape + ";");
break;
}
case CONTENIDO:
//guarda el caracter escapado o ; sin ser de escape
if (estado == Estado.CONTENIDO) {
contenido += c;
break;
}
case ETIQUETA:
case ETIQUETA_ABERTURA:
case ETIQUETA_CIERRE:
//si no es de contenido es de etiqueta
etiqueta += c;
break;
default:
token = new Token(TokenType.ERROR,
"Error, estado: " + estado.name());
break;
}
break;
//carácteres especiales
case '<':
switch (estado) {
case ETIQUETA:
case ETIQUETA_ABERTURA:
case ETIQUETA_CIERRE:
//error
System.err.println("Error");
break;
case CONTENIDO:
estado = Estado.ETIQUETA;
if (!contenido.equals("")) {
token = new Token(TokenType.CONTENT, contenido);
}
contenido = "";
etiqueta = "";
break;
default:
token = new Token(TokenType.ERROR,
"Error, estado: " + estado.name());
break;
}
break;
case '>':
switch (estado) {
case ETIQUETA:
//error etiqueta vacia
token = new Token(TokenType.ERROR,
"Error etiqueta vacía: " + estado.name());
break;
case ETIQUETA_CIERRE:
token = new Token(TokenType.CLOSE_TAG, etiqueta);
estado = Estado.CONTENIDO;
break;
case ETIQUETA_ABERTURA:
estado = Estado.CONTENIDO;
token = new Token(TokenType.OPEN_TAG, etiqueta);
break;
case CONTENIDO:
//error
token = new Token(TokenType.ERROR,
"Error >, estado: " + estado.name());
break;
default:
token = new Token(TokenType.ERROR,
"Error, estado: " + estado.name());
break;
}
break;
case '/':
switch (estado) {
case ETIQUETA:
estado = Estado.ETIQUETA_CIERRE;
break;
case CONTENIDO:
contenido += c;
break;
case ETIQUETA_ABERTURA:
case ETIQUETA_CIERRE:
default:
token = new Token(TokenType.ERROR,
"Error, estado: " + estado.name());
break;
}
break;
//otros carácteres
default:
switch (estado) {
case ESCAPE:
escape += c;
break;
case ETIQUETA:
estado = Estado.ETIQUETA_ABERTURA;
case ETIQUETA_ABERTURA:
case ETIQUETA_CIERRE:
etiqueta += c;
break;
case CONTENIDO:
contenido += c;
break;
default:
token = new Token(TokenType.ERROR,
"Error, estado: " + estado.name());
break;
}
break;
}
}
return token;
}
}
El parser analiza los tokens que le pasa el lexer. Las etiquetas presentes en los informes son las relacionadas con tablas: TABLE, TR, TH y TD, son las únicas que analiza. Según va analizando tokens va devolviendo cadenas de texto de forma que se puede componer un archivo .csv de excel (valores entre comillas y separados por punto y coma).
import java.util.Scanner;
/**
* Parser que genera un texto en .csv según los tokens que se le pasen.
* No hace comprobaciones de que el informe esté bien formado.
* @author Agustin Herranz
*/
public class Parser {
private Lexer.Token lastToken;
private Lexer.Token newToken;
private int tagNumTable;
private int tagNumTr;
private int tagNumTd;
private int tagNumTrInTable;
private int tagNumTdInTr;
/**
* Constructor de la clase parser
*/
public Parser(){
this.tagNumTable = 0;
this.tagNumTd = 0;
this.tagNumTdInTr = 0;
this.tagNumTr = 0;
this.tagNumTrInTable = 0;
this.newToken = null;
}
/**
* Devuelve texto con el que componer el archivo .csv, según los tokens que
* se le pasan.
* @param token
* @return texto correspondiente a cada token para formar el .csv
*/
public String parse(Lexer.Token token){
lastToken = newToken;
newToken = token;
Scanner sc = new Scanner(newToken.contenido);
String tag = "";
if(sc.hasNext()){
tag = sc.next().toUpperCase();
}
String text = "";
switch(newToken.tipo){
case CONTENT:
text = token.contenido;
//escapar contenido .csv: " por ""
if(text != null){
text = text.replace("\"", "\"\"");
}
break;
case OPEN_TAG:
switch(tag){
case "TABLE":
this.tagNumTable += 1;
this.tagNumTrInTable = 0;
break;
case "TR":
this.tagNumTr += 1;
this.tagNumTrInTable += 1;
this.tagNumTdInTr = 0;
break;
case "TH":
case "TD":
text = "\"";
this.tagNumTd += 1;
this.tagNumTdInTr += 1;
break;
default:
//etiqueta no soportada
break;
}
break;
case CLOSE_TAG:
switch(tag){
case "TABLE":
//text = "\r\n";
break;
case "TR":
text = "\n";
break;
case "TH":
case "TD":
text = "\";";
break;
default:
//etiqueta no soportada
break;
}
break;
case ERROR:
text = " ** ERROR ** ";
break;
default:
break;
}
return text;
}
}
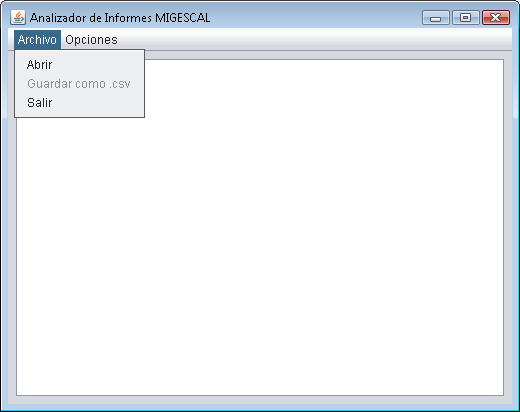
Para hacer más fácil su uso he creado una interfaz con swing, a base de ejemplos encontrados por itnernet. Abre el archivo y muestra el resultado del parser en un área de texto. Si se ha realizado sin errores permite guardarlo como archivo .csv. También incluye un apartado de opciones para establecer la codificación tanto del archivo de entrada como del de salida.
Incluyo a continuación el código fuente y el .jar por si a alguién le es de utilidad: Informes